Интернет-базиран конкорданс към Корпуса на българската политическа и журналистическа реч
Hosted by 
Корпусът по политическа и журналистическа реч включва текстове и лингвистични анотации на интервюта и изказвания на политици и журналисти. Интервютата са събрани от публикации в пресата или са транскрибирани от предавания по електронните медии. Източниците на изказванията са парламентарните дебати, партийните форуми и други обществени прояви.
Корпусът на българската политическа и журналистическа реч се разработва в рамките на Центъра за изследване на политическата и журналистическата реч.
В тази версия е представен Интернет-базиран конкорданс на търсена словоформа (или съчетание от словоформи) в корпус от чисти (неанотирани) текстове на български език. Конкорданс означава представянето на дадена дума или израз спрямо техния десен и ляв контекст. Чисти, или неанотирани, текстове са тези, при които няма допълнителна лингвистична метаинформация (напр. морфологична или синтактична).
Следващите версии ще включват и допълнителна лингвистична информация над текстовете. Лингвистичната анотация включва следните нива: морфологични етикети (глагол, съществително име и под.), лематизация (свеждане на словоформата до нейната основна форма), информация за говорещия (за политиците се отбелязва партийната принадлежност и заеманият пост; за журналистите - медията, за която работят), информация за типа на изказването (субективно или обективно; отношение към темата на изказването - неутрално, положително или отрицателно).
Целта на корпуса е да бъде използван за лингвистични, политоложки и социологически изследвания върху езика и поведението на политици и журналисти.
Интернет-базираният конкорданс е мрежова услуга, имплементирана в системата WebCLaRK – система за езикови услуги по Интернет. Тя може да работи върху различни корпуси. Достъпът до услугата е напълно свободен. Търсенето може да се прави само по словоформи, не по леми (лексеми). По-нататък се дават конкретни насоки за ползването на конкорданса. Нека първо започнем с общо запознаване.
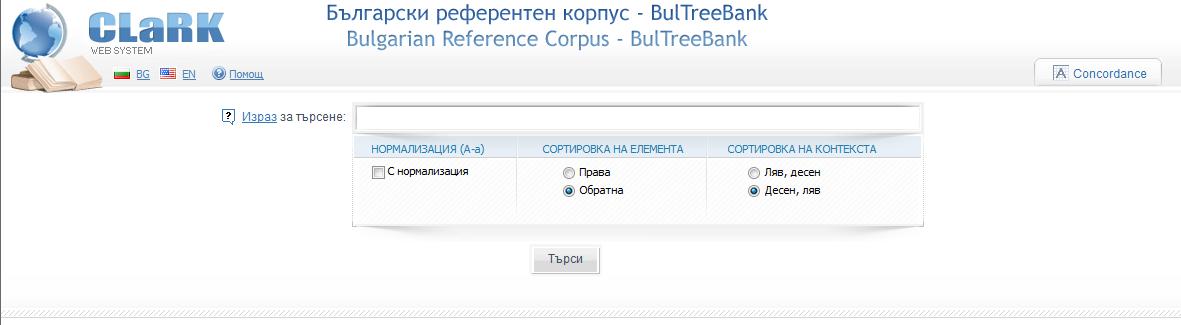
Системата е организирана по следния начин: има прозорец, в който се записва изразът за търсене. Ако бутонът НОРМАЛИЗАЦИЯ (А-а) е изключен, то търсенето на елемента става по начина, по който е записан – с всички малки букви (напр. роза), с начална главна буква (Роза) или с всички главни букви (РОЗА). Ако бутонът е включен, тогава намерените елементи включват всички изписвания, които се срещат в корпуса, независимо от начина, по който потребителят е дал заявката.
По премълчаване сортировката на търсения елемент е обратна (СОРТИРОВКА НА ЕЛЕМЕНТА). Това означава, че намерените елементи се сортират по завършеците си. Ако потребителят желае те да бъдат сортирани по началата си, трябва да маркира Права сортировка. По подобен начин елементът се показва сортиран по Десен контекст (СОРТИРОВКА НА КОНТЕКСТА). Ако потребителят желае да има сортировка по левия контекст, трябва да маркира опцията Ляв, десен. Ще отбележим, че сортировките могат да се направят и след като се появи материалът.
След като е написан изразът за търсене – в случая – думата роза с включен бутон за нормализация, се натиска бутонът Търси. При успешно търсене се появява таблица с примери. В средната колона (Намерен елемент) е записан търсеният елемент или съчетание от елементи. В лявата и дясната колона са съответно левият и десният контекст. Те имат ограничение до 18 думи и/или пунктуационни знаци. Таблицата показва до 300 примера, за да се ориентира потребителят дали резултатът отговаря на неговите очаквания. Корпусът е кодиран в XML. При извличането на контекстите на намерените думи или фрази може да се използва текст от повече от един XML елемент (например от два съседни параграфа). Границите на тези елементи се маркират с низа ***BR***. Потребителят може да запази на своя компютър по-голямо количество примери. Ограничението на техния брой е 3000. По-надолу се дават указания как да се запазят всички примери. Ако потребителят има нужда от повече от 3000 примера, трябва да се обърне към нас. Вдясно от прозореца за търсене има и прозорец за статистика на намерените словоформи. В случая словоформата се среща с три изписвания в корпуса – с първа главна буква (113 пъти), с малки букви (205 пъти) и с всички главни букви (4 пъти).
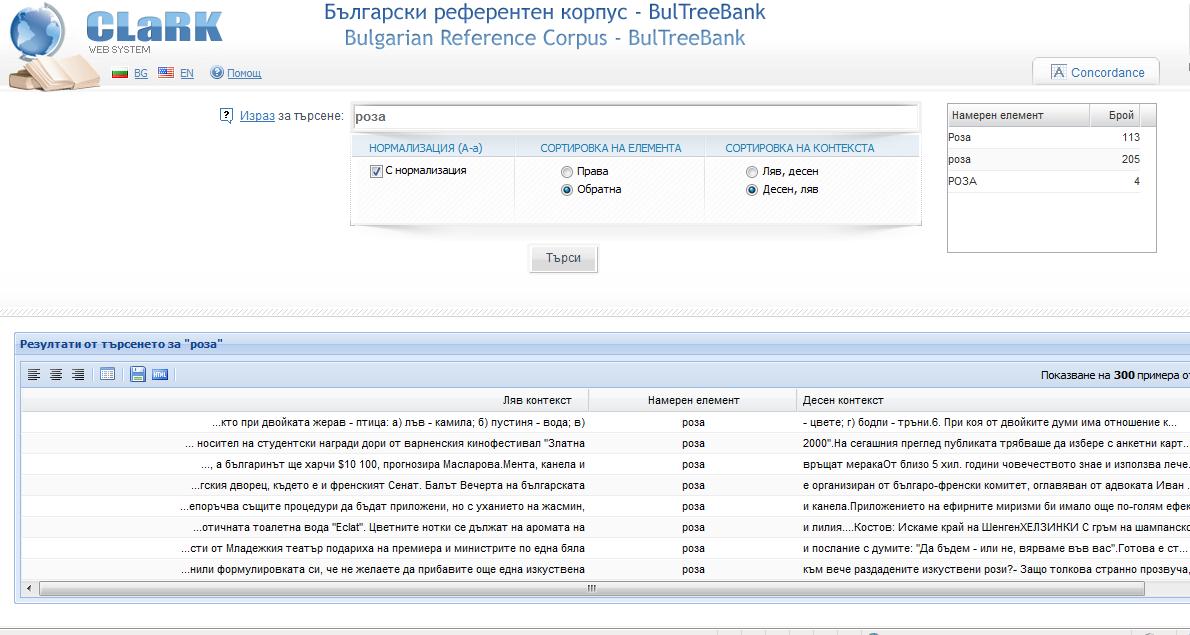
Обяснения на последователностите от стъпки при търсене в WebCLaRK.
1. Израз за търсене
За да бъде успешно търсенето, потребителят трябва да знае как да запише заявката си. Заявките представляват регулярни изрази, които се съпоставят с текстовете в корпуса. Такъв регулярен израз се състои от изрази за словоформи и специални оператори. Израз за словоформа се съпоставя на една словоформа в корпуса. Такъв израз се състои от последователност от символи (букви, цифри, пунктуационни знаци) и заместващи символи. Буквите, цифрите, пунктуационните знаци се съпоставят на себе си (при нормализация на главни и малки букви). Заместващите символи са #, @ и %. Заместващият символ # се съпоставя на произволен низ от символи в рамките на една словоформа, включително празния низ. Заместващият символ @ се съпоставя на нула или един произволен символ. Заместващия символ % се съпоставя на един произволен символ. Имайте предвид, че думите в корпуса не съдържат интервали и препинателни знаци (с изключение на тире). Когато се търси една единствена словоформа, тя се записва в прозореца за търсене. По-нататък представяме най-честите варианти за търсене:
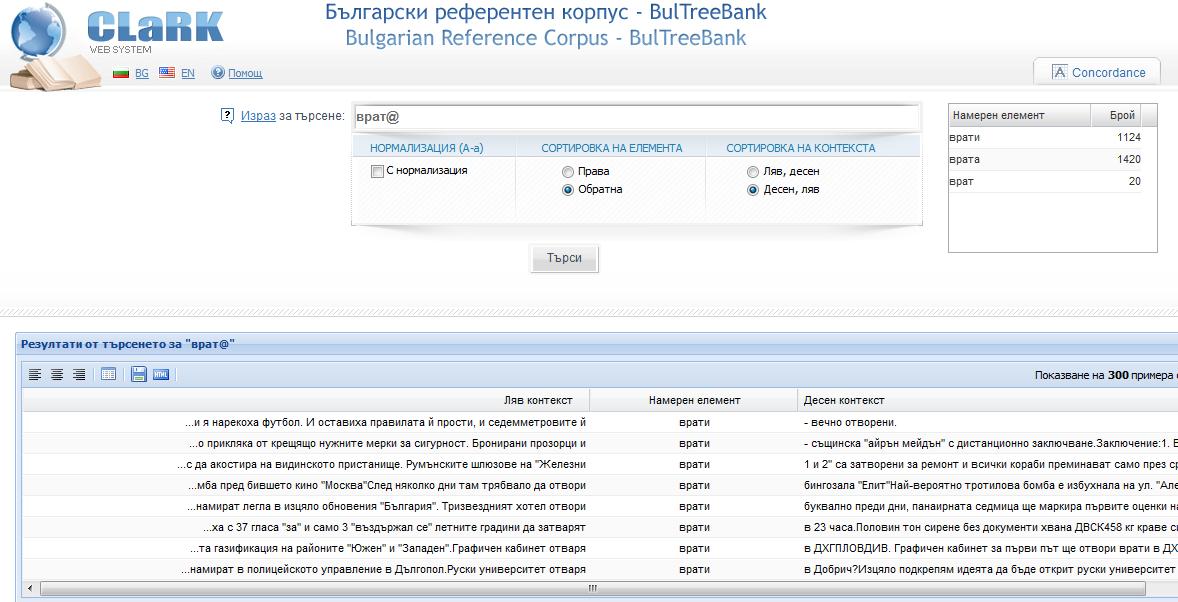
1. Когато търсим дадена дума, но и нейни форми, които се различават с една буква от думата, може да използваме символа @. Например, за да намерим формите врат и вратА, пишем израза: врат@. Разбира се, трябва да се отчете омонимията между членуваната с кратък член форма за м.р., ед. ч. (вратА) и нечленуваната форма за ж.р., ед.ч. (вратА). Също така се появява и нечленуваната форма за ж.р., мн.ч (вратИ), която в случая се игнорира:
2. Когато искаме да обозначим самата дума, но и думи, които имат повече променливи след нея, използваме символа #. Например, за да намерим думата врат плюс думи, които да я включват, пишем израза: врат#. Виждаме, че освен срещания на врат, се появяват словоформи като вратА, вратЪТ, вратАР, вратАРКА, вратАРСКИЯ и др.

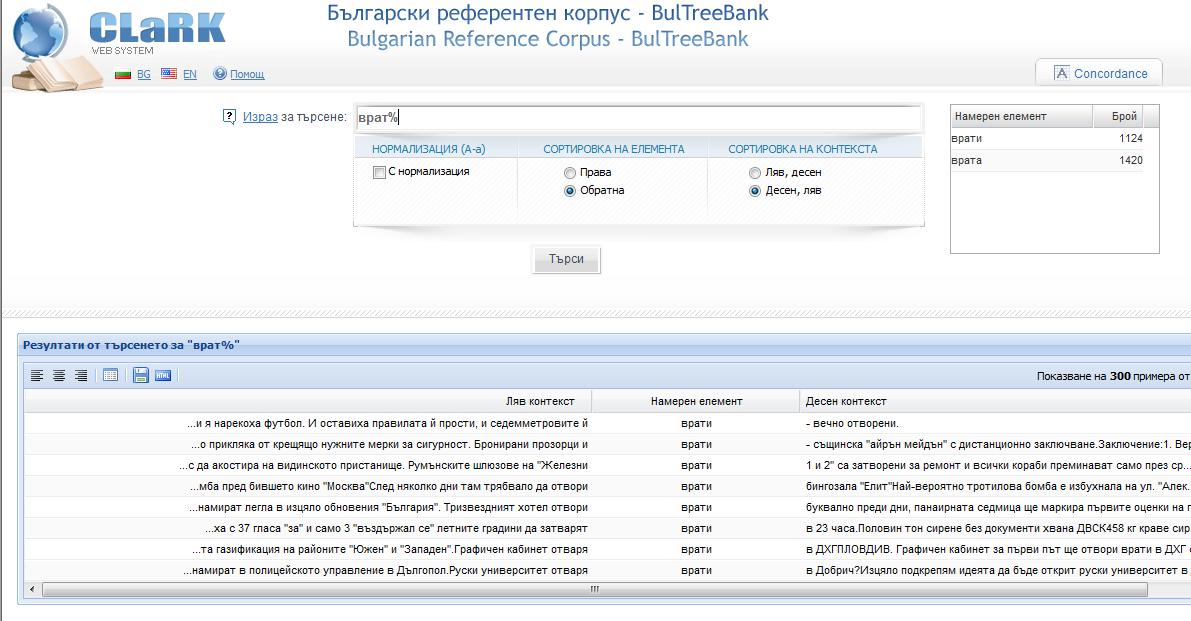
3. Когато искаме да обозначим точно една променлива, използваме символа %. Например, за да намерим формите вратА и вратИ, пишем израза: врат%.
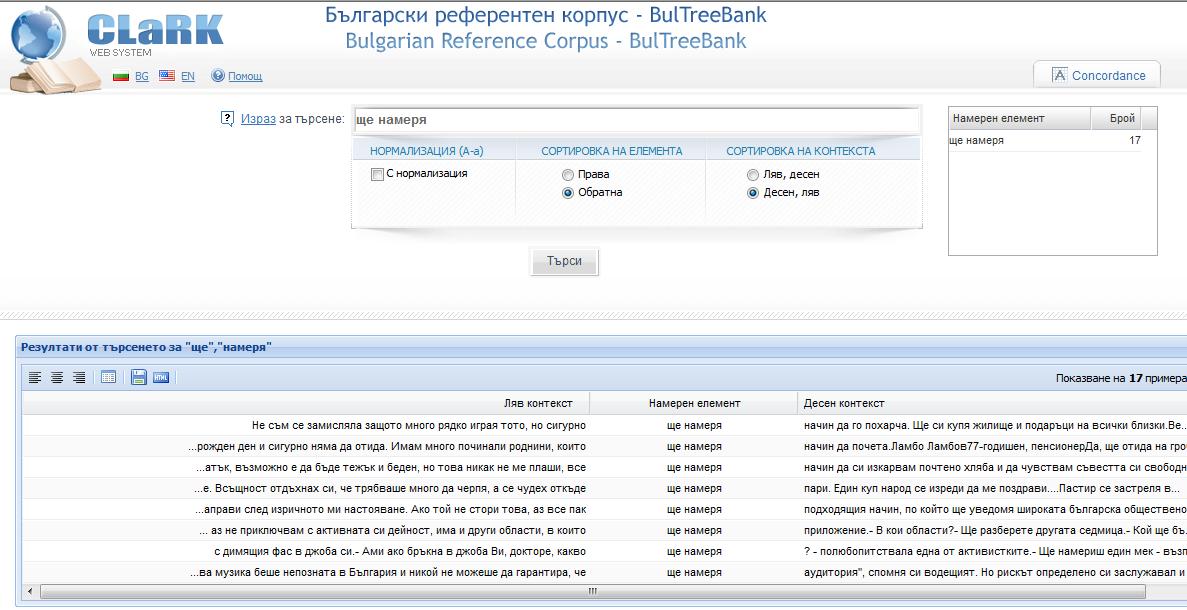
4. Когато искаме да напишем израз за дума плюс друга дума, пишем двете думи. Например, за да намерим израза ще намеря, пишем: ще намеря.
5. Разбира се, може да приложим и символите от точки 1, 2 и 3.
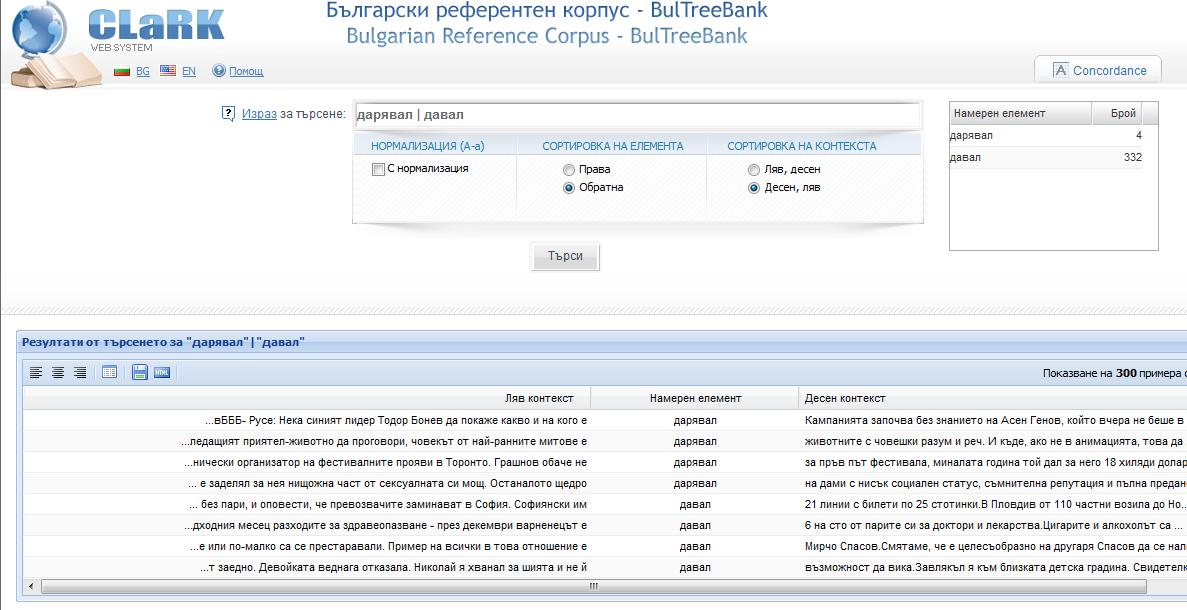
6. Когато искаме да зададем дизюнкция (т.е. една ИЛИ друга дума), използваме отвесна черта (|). Например, за да намерим формите дарявал или давал, пишем израза: дарявал | давал. Появяват се срещания и за двете словоформи.
2. Наблюдаване на резултатите
2.1 Статистика
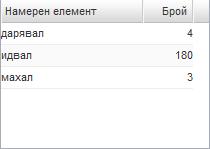
В прозореца за статистика (вдясно) се появява броят на срещанията на словоформата/словоформите, които са намерени. Например в прозореца по-долу са показани срещанията на словоформите дарявал, идвал и махал.
2.2 Намерен израз
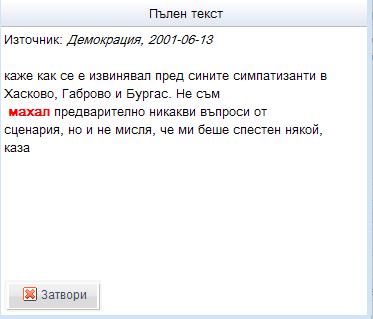
Ако кликнете два пъти върху избран намерен израз, се появява голям прозорец с част от контекста, както и с източника, откъдето е изваден примерът.
2.3 Контекст
Ако се кликне върху реда с левия или десния контекст, се появява голям прозорец с тази част на текста.
2.4 Опции
- Опцията Подравняване в средата разполага намерения елемент в средата:

- Опцията Подравняване вляво приближава намерения елемент по-близо до левия контекст:

- Опцията Подравняване вдясно приближава намерения елемент по-близо до десния контекст:

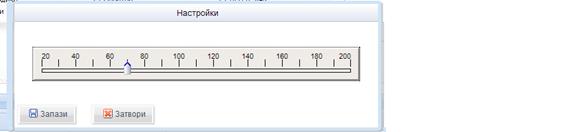
- Опцията Настройване на броя символи за показване позволява на потребителя да контролира дължината на десния и левия контекст:

Ето и самата таблица:
3. Запазване на файла с намерените резултати
Тъй като системата показва в таблицата само до 300 примера от всичките намерени, потребителят може да желае да разгледа всички намерени примери (до 3000). Това може да бъде направено в два формата - XML и HTML.
Потребителят може да запази целия файл с намерени резултати в XML формат, като натисне върху иконата за XML документи:

Появява се диалогов прозорец, с помощта на който потребителят може да запази XML документа с всички примери.
Форматът на този XML документ е като формата, използван за конкорданси в системата CLaRK (http://www.bultreebank.org/clark/index.html). В този формат всеки ред се представя по следния начин:
<L>
<LC> ляв контекст </LC>
<I> търсен пример </I>
<RC> десен контекст </RC>
</L>
Такъв документ може да се отвори локално (на компютъра на потребителя) и да се обработва по-нататък според нуждите на потребителя.
Потребителят може да запази целия файл с намерени резултати в HTML формат, като натисне върху иконата за HTML документи:

Този документ може да бъде разглеждан в интернет браузър или да се отвори в MS Word и да се наблюдава там. Този формат е удобен да се копират примерите в други документи и подобни.
4. Примерни изрази за търсене
Тук даваме няколко примерни израза, които да служат като отправна точка за дефиниране на нови търсения. Ако е включена нормализацията, резултатът ще включва примери с големи и с малки букви. В противен случай ще бъдат търсени примери с точно съвпадение.
| Израз | Очакван резултат | |
| политика | до 3000 примера на срещания на словоформата "политика" | |
| полити# | до 3000 примера на срещания на словоформи, започващи с "полити" | |
| политик | политика | политикът | политици | политиците | до 3000 примера на срещания на словоформите "политик", "политика", "политикът", "политици" и "политиците" | |
| (ми | ти | му | й | ни | ви | им)+ | до 3000 примера на срещания на "ми", "ти", "му", "й", "ни", "ви" и "им" | |
| (ми | ти | му | й | ни | ви | им), (ми | ти | му | й | ни | ви | им)+ | до 3000 примера на срещания на комбинации от две или повече от словоформите "ми", "ти", "му", "й", "ни", "ви" и "им". Примери като: Майка му им се е обадила. Децата ни ни изпревариха. | |
| (да | ще),(ми | ти | му | й | ни | ви | им | ме | те | го | я | ги | си | се | ли | не)*,(съм | си | е | сме | сте | са),(#л | #ла | #ло | #ли) | до 3000 примера на срещания на потенциални аналитични глаголни форми. Примери като: Иван ще им я е дал. Децата да са легнали до 10 часа. |
5. Обратна връзка
По всички въпроси може да пишете на webclark@bultreebank.org. Коментари за допълнения, съобщения за грешки и други са повече от добре дошли.
Ограничението от 3000 броя примери е с цел да не се прехвърлят големи файлове по мрежата. Ако това ограничение ви създава неудобство и имате нужда от повече примери, пишете ни. При възможност ще ви предоставим по-голям брой примери или директен достъп до корпуса.